
Using AI to create my cat's final adventure

Our cat Elvis reached the end of the road this week.
He was an outdoorsy, adventurous cat - a trait not reflected in the ‘memory’ video Apple’s AI created from my many photos of him in repose around the various houses we’ve lived in over the past decade.
So, I thought I’d use AI to take him on one final globetrotting adventure, whilst simultaneously road-testing some of the latest image and video generation models - particularly Seedream 4, which was released by ByteDance a couple of weeks ago and is now beating Google’s Nano Banana in the image generation leaderboards).
The eagle-eyed will spot a few AI oddities (e.g. the jeep canopy disappearing mid-shot, a very synthetic looking Vegas audience). However, it’s striking how much the quality of AI video has improved since I made a movie trailer for an imagined sequel to The Shining last April.
Almost all of the assets I used were generated with a single natural language prompt (e.g. “Tourist style selfie composition with cat holding phone/camera with paw, Eiffel Tower perfectly framed in background, wearing tiny beret, classic Paris tourist moment, golden hour lighting”). Where I did have to make edits, that too was using natural language (e.g. “remove the eiffel tower in the distance, make the phone a bit bigger and make the beret deep red”).


Also notable is that I only left Freepik once, to generate music using Suno (Freepik does offer music generation using Google’s Lyria but it doesn’t do vocals). When I made the trailer last April, I used seven different AI tools.
The process
For those interested in the process:
I had the idea and drafted a script (sans AI 😲)
I brainstormed a shot list with Claude

I asked Claude to draft some corresponding image prompts

I tweaked the image prompts and put them into Seedream 4 and FLUX.1 Kontext (via Freepik) with two reference images of our cat and one of his favourite armchair (an IKEA EKENÄSET, thanks for asking)
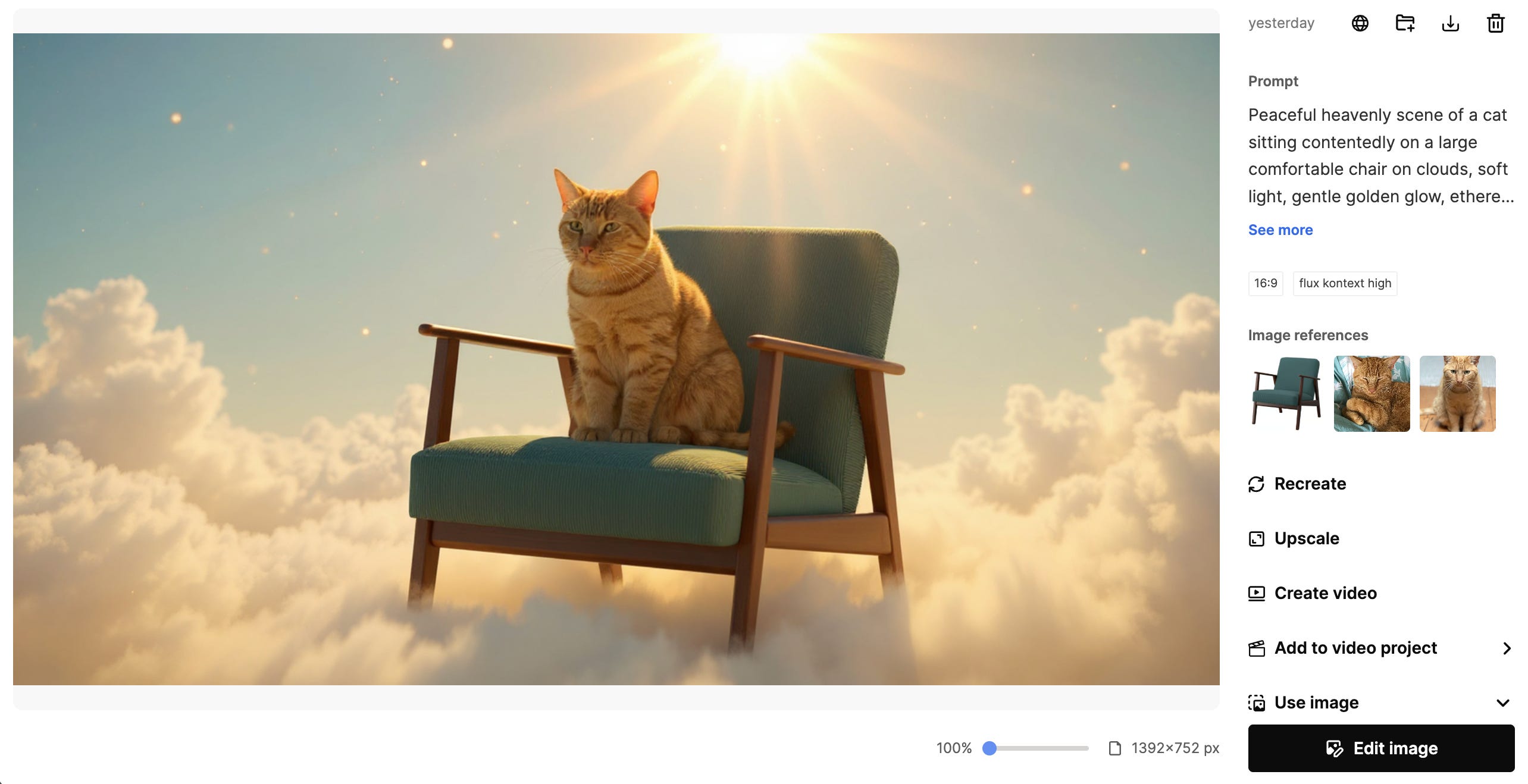
I requested edits to a few of the images, also using Seedream 4 and FLUX.1 Kontext
I then animated the images using KLING 2.1 and Google Veo 3 Fast (also via Freepik)
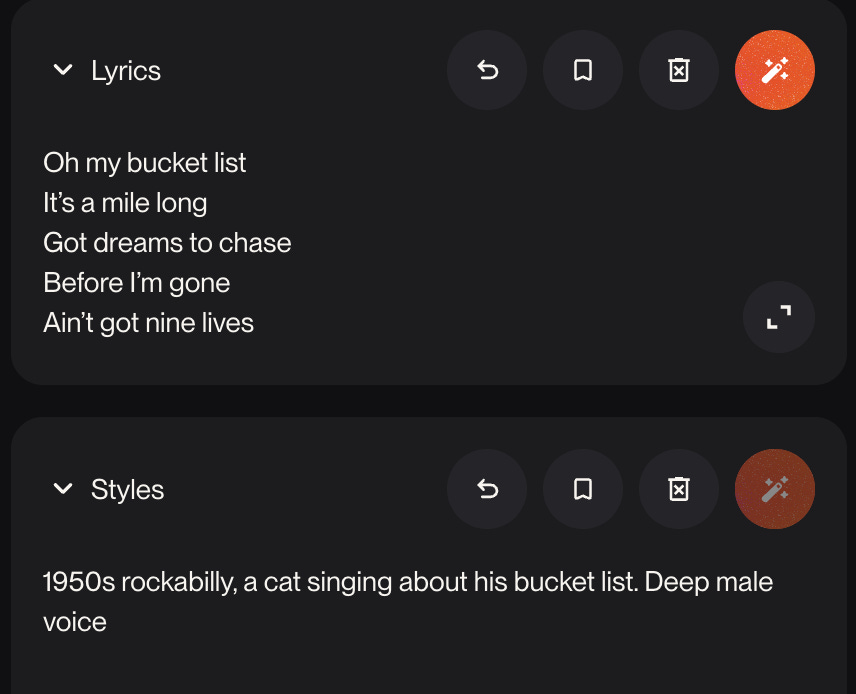
I tweaked the script and generated the voiceover audio using ElevenLabs v3 (via Freepik)
I generated the backing track, and music for the Vegas segment, using Suno
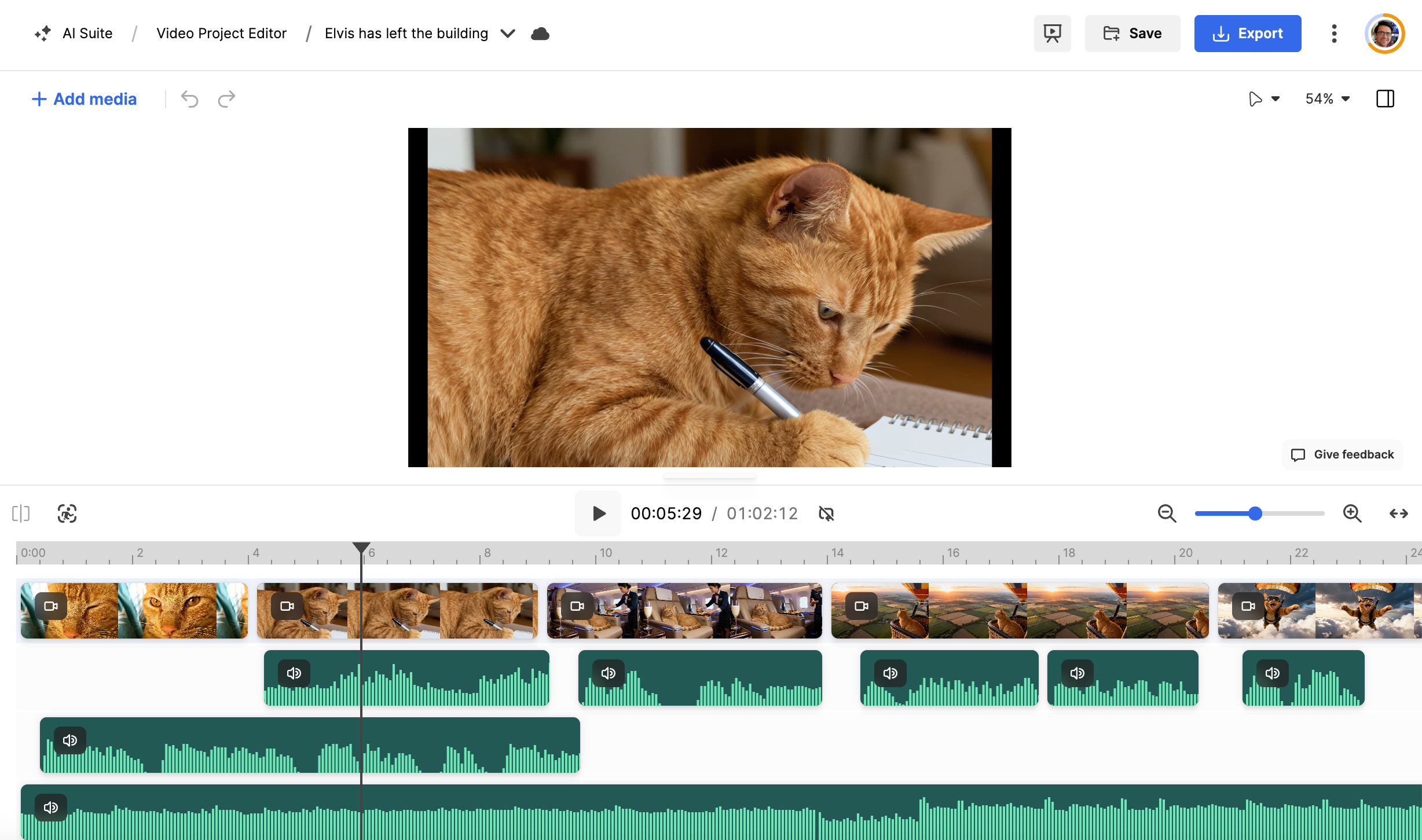
I then stitched it all together using Freepik’s Video Project Editor, adding a few sound effects and the final text slide
Limitations/creative choices
I imposed a few limitations on the process (e.g. only one re-edit allowed per image/video) to avoid me spending too much time/money/GPU cycles1 on a video that was intended as a lighthearted tribute to a family pet and a demonstration of what someone without any background or training in video production can achieve with the current generation of AI tools. I also made some creative choices. I wanted the cat to look like Elvis but wasn’t aiming for true photo realism, as the scenario is inherently unrealistic and comedic. Whilst now eminently doable, I opted not to lip sync any audio and instead furnish Elvis with an internal monologue.
Cost
All the generations, including a few I didn’t use in the final edit, used up about 34,000 of the 45,000 credits I get as part of my £38.40 Freepik Premium+ monthly plan, so it worked out at around £29. It would have been possible to make the video much more cheaply using less state-of-the-art models (Freepik offers unlimited usage of open-source video model Wan 2.2). Equally, I could have burnt through more credits using more sophisticated models.
Conclusions
Comparing the quality of output and ease of production with last April, it’s clear we are on a trajectory where it will soon be trivial for anyone to generate serviceable video clips with appropriate audio and consistent characters, without the obvious tells that plagued early AI-generated video.
We are also converging on a point where making edits to video will be as trivial as verbalising the change you want to see.
To date, AI video generation has been mostly limited to single 5-10 second clips, which then have to be stitched together to create longer scenes. However, that too is starting to change with the advent of autoregressive models capable of generating 60 second videos.
As a new path to video creation and editing continues to mature, the question of what stories to tell and how remains largely in human hands. AI tools do not magically bestow storytelling abilities on those that use them and are - imho - best in a supporting role when it comes to writing scripts and song lyrics.
To what extent AI models can get better at emulating the idiosyncrasies and discernment of human storytellers remains to be seen (I would be equally sceptical of anyone telling you this is either inevitable or impossible).
It’s been interesting to see the opprobrium heaped upon Mississippi poet/lyricist Telisha Jones for signing a record deal for songs set to music by Suno and voiced by her AI-generated alter ego, Xania Monet. Our discomfort at AI performing functions previously the exclusive domain of humans (composing and singing) is so strong that Jones has been cast not as an enterprising lyricist, in the tradition of Hammerstein, Tim Rice, and Bernie Taupin, but as a huckster.
Where’s the TV & film industry at with AI generation video?
After a couple of years of caution, I’m seeing a gradual increase in the use of AI-generated video in film and TV production.
In July, Netflix Co-CEO Ted Sarandos revealed “the very first GenAI final footage to appear on screen in a Netflix original series or film” in response to a question on the company’s Q2 2025 earnings call. The sequence, from the final episode of Argentinian sci-fi comic book adaptation, El Eternauta (English title: The Eternaut), shows a high-rise building collapsing. Sarandos said the sequence “was completed 10x faster than it could have been completed with…traditional VFX tools and workflows.”

Sarandos prefaced the comments about El Eternauta with these remarks: “We remain convinced that AI represents an incredible opportunity to help creators make films and series better, not just cheaper. They're AI-powered creator tools. So this is real people doing real work with better tools. Our creators are already seeing the benefits in production through pre-visualization and shot planning work and certainly, visual effects. It used to be that only big budget projects would have access to advanced visual effects like de-aging.”
Whilst the sequence itself is brief and underwhelming, these remarks from Sarandos represent another milestone in the normalisation of on-screen AI use in high-end drama. VFX that would otherwise have been prohibitively expensive is emerging as a defensible toe-in-the-water for on-screen use of AI.
Last week FT drama (no, me neither) released Recall Me Maybe, a 13-minute drama penned by David Baddiel, which makes use of generative AI to render snatches of a younger Stephen Fry. The footage is AI-generated in the narrative, affording the producers some latitude in terms of quality/verisimilitude (“Don’t worry if the images look a bit strange, they self-refine over time”).

Whilst any use of AI-generated video tends to draw criticism, we’re starting to see more producers tentatively exploring its potential to render sequences that would have been impossible or uneconomical to bring to life using traditional production techniques (suffice it to say, I would not have attempted to bring my Elvis tribute to life using live action animatronics…)
AI video generation is relatively energy intensive. I carbon offset my AI usage via Ecologi.