


The AI image generators are coming for Photoshop
Plus updated AI image generators comparison matrix

The first generation of AI image generators didn’t have much in the way of user interface.
Most were only accessible via an API and/or a basic website, with text prompts the primary means of controlling the output.
Before May, market-leader Midjourney could only be prompted via a Discord server, with simple variations requiring arcane parameters with unforgiving syntax (e.g. generating landscape images required the user to add ‘--ar 16:9’ to the prompt).

DALL·E 3 is predominantly accessed via ChatGPT and Microsoft Copilot, which rewrite the prompts before passing them on to DALL·E, reducing the user’s control over the output.

When I did a comparison of AI image generators in April, Adobe Firefly was notable for having a vaguely 21st century interface, although interacting with any of the drop-downs, radio buttons or sliders would overwrite the previously generated image(s).
Since April, some new image generators have launched and some existing players have added some significant new capabilities.
As well as material improvements to the underlying models, resulting in faster generations, better prompt adherence and text rendering, there’s been a shift towards more sophisticated canvas-based interfaces, where images and text can be combined and reworked.
Here’s a quick round up of developments in AI image generation over the last 8 months:
Imagen
In May, Google announced version 3 of its flagship AI image generator, Imagen, although it wasn’t until August that it was made available in the US via ImageFX and October that it was made available globally via Gemini.
Midjourney
Version 6.1 of Midjourney arrived at the end of July, with minor improvements over v6 all round. It finally opened up its website to all users in August. October saw the introduction of Editor, enabling annual subscribers to upload any image and use AI to edit it, expand it or retexture it.
FLUX
In August, Black Forest Labs emerged from stealth and released the first versions of its FLUX.1 model. They were fast, producing high quality images with strong prompt adherence and text rendering. They also helped popularise LoRA - a technique for fine-tuning models, which has made it much easier to maintain a consistent subject.
FLUX 1.1 Pro models were released in early October and quickly ascended to the top of the Artificial Analysis Image Arena leaderboard (where users rate the output of different models).
Black Forest Labs doesn’t offer hosted versions of its Flux models, but you can access them via creator platforms like Freepik and Krea or via model aggregators like fal.ai, Replicate and Together AI.
Ideogram
In August, Ideogram released version 2.0 of its eponymous model, which introduced styles and colour palette control and improved its prompt adherence, photorealism and text rendering.
In October, Ideogram added Canvas, an infinite canvas for organising, generating, editing and combining images. Equipped with Layers, tools like Magic Fill and Extend and the ability to edit existing images, Canvas moved Ideogram away from rinse and repeat text-to-image prompter towards Photoshop’s turf.
Recraft
In late October, a mysterious new model known as Red Panda appeared at the top of the Artificial Analysis Image Arena leaderboard. Subsequently unmasked as Recraft V3, the new model was accompanied by a new user interface for Recraft. Rather than individual generated images being the default presentation, users are invited to engage with ‘Projects’ which correspond to an extensible canvas, with similar, but slightly more advanced, functionality to Ideogram’s Canvas.
Recraft also enables user to create vector images (which can be scaled without losing resolution) and convert raster images into vector images.
Recraft’s wealth of functionality has created a more complex interface which requires some learning. Fortunately they’ve done a better job than most AI companies (*glares at OpenAI*) at providing simple tutorials.
Runway Frames
Last month, Runway, known primarily for its video generation models, released a new image generation model, Frames, with the promise of “unprecedented stylistic control”. However, access to the model is being rolled out gradually to Runway subscribers and I don’t seem to have access yet.
Luma Dream Machine
Initially launched as a text-to-video generator in June, version 1.6 of Dream Machine arrived in November and introduced standalone image generation and a new user interface in the form of Boards.
The Boards UI encourages the user to create separate project-based workspaces and to view their first generations from a prompt as the beginning of an iterative and collaborative process. Key words from the prompt are highlighted and clickable, with alternative terms auto-suggested. Underneath are three calls to action: ‘Show More’, ‘Brainstorm’ and ‘Reply’. ‘Show More’ gives you another 4 generations in response to your original prompt. ‘Brainstorm’ provides suggestions of different creative directions and redrafts your original prompt accordingly. ‘Reply’ encourages you to refine the images through conversation. Any evolutions of the prompt are presented in a full-page vertical scroll, with prompts on the left and generations on the right.
Last week Luma unveiled two new image generation models, Photon and Photon Flash.
Aurora
As much as I dislike giving airtime to anything Elon Musk has a hand in, it would be remiss of me not to mention the release this week of a new AI image generation model in the form of Aurora, which is accessible via Grok on X. The quality of the outputs looks pretty decent but there’s very limited ability to control and refine so I won’t be adding Aurora to my comparison matrix just yet (I’m also not adding models which don’t yet have an accessible front end - e.g. Amazon Nova).
Adobe Firefly
Of course, Adobe hasn’t been taking all of this lying down, rolling out v3 of its Firefly Image model, adding Generative Expand to the Firefly web app and beefing up Photoshop’s AI feature set.
So, what impact have all of those changes had on the relative strengths and weaknesses of the different AI image generators? Here’s an updated comparison matrix (click/tap to enlarge).

To inform my star ratings, I gave each AI image generator five challenging prompts, testing their ability to generate both photorealistic and more stylistic output, to construct novel images that won’t have been within their training data and to render text. I also tried to test their approach to trademarks and their propensity to generate stereotypes.
The prompts
My first prompt (‘Santa Claus in a hot tub drinking from a glass Coke bottle’) split the pack right out of the gate. DALL·E, DreamStudio, Leonardo.Ai and Runway all produced images with an obviously-generated-by-AI aesthetic, with DALL·E the worst offender (although to be fair this prompt didn’t specifically ask for a photo).
iStock flat refused to generated anything on account of the word ‘Coke’ in the prompt. Firefly told me it had removed the word ‘Coke’ and generated images with unlabeled bottles.
Two of the images Firefly generated featured a female santa; all had the stock photography aesthetic that is Firefly’s achilles heel when it comes to generating photorealistic output.
Midjourney, Imagen, Ideogram, Dream Machine, Recraft and Freepik all did a pretty decent job, although only Freepik rendered both the iconic logo and bottle shape.
Winner: Freepik🥇

A lot of the generators struggled with my second prompt (‘A Pixar-style animated image of a crescent-shaped croissant with hands on his hips, standing in a bakery. He is wearing a crown on his head and a royal cape on his back. There are other baked goods in the background’). Without many examples of anthropomorphised, regally attired croissants in their training data, the models struggled to combine all the elements. Only DALL·E, Imagen, Dream Machine and Recraft managed an obvious crescent shape.
Midjourney, Freepik, Leonardo.Ai and Runway all produced pastry shapes that would have got a rough time from the Bake Off judges in a croissant challenge.
DreamStudio’s generation was probably the most Pixar of the bunch, although missed other key elements of the prompt (the croissant and the cape).
iStock produced the least aesthetic image; a monstrous amalgamation of stock photography and line art (and those hands are definitely not on hips).
Dream Machine and Recraft also fail the hip test.
It’s close between DALL·E and Imagen, but Imagen just takes it.
Winner: Imagen🥇

My third prompt (‘macro product photography of a rainbow iphone 15 pro max, studio lighting’) tested the generators’ ability to render a very familiar, precisely-machined inorganic object in a particular style with a colour scheme that wouldn’t be in their training images.
Both Firefly and iStock refused to generate an image (iPhone no doubt being on their ‘do not render’ list).
Freepik, DreamStudio and Runway all failed to render the iPhone 15 Pro’s distinctive camera array, whilst Imagen and Leonardo.Ai failed to deliver on the rainbow element of the brief.
DALL·E and Recraft got the power button on the wrong side and included some distorted text, leaving a photo finish between Midjourney and Ideogram.
Winner: Midjourney🥇

My fourth prompt (‘A close-up shot of brass plaque next to a painted teal door. The plaque reads "DAN TAYLOR-WATT", then on another line" DIGITAL CONSULTANT" in a serif font’) aimed to test both text rendering and the ability to correctly position objects relative to one another.
iStock, Firefly, DreamStudio and Runway really struggled here. Midjourney, DALL·E and Freepik all made small mistakes with the text. Imagen, Ideogram, Dream Machine, Recraft and Leonardo.Ai all nailed the text, although Imagen rendered a sans-serif font and Recraft put the plaque on the door rather than next to it.
It’s a close call between Ideogram, Dream Machine and Leonardo.Ai, although Ideogram just takes it for its plausible rendering of the wall and door.
Winner: Ideogram🥇

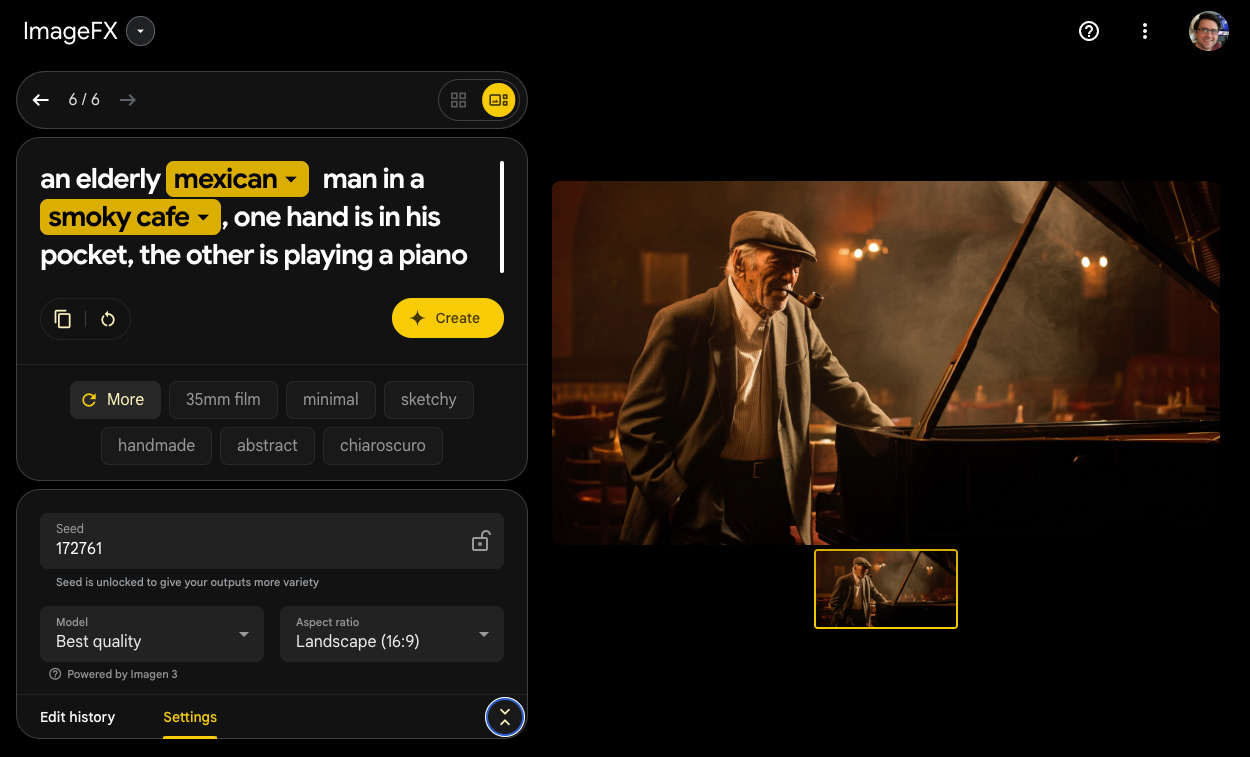
My final prompt (‘an elderly mexican man in a smoky cafe, one hand is in his pocket, the other is playing a piano’) sought to test the models’ ability to render faces and hands, create mise en scène and override a common depiction within their training data (most images of pianists show two hands on the piano), with a bonus check of inclination towards national stereotypes.
DALL·E, DreamStudio, Leonardo.Ai and Runway produced the most obviously AI-generated images.
Most models struggled to render convincing hands and only Ideogram and Freepik definitively managed one hand in pocket and one on the piano (Imagen, Dream Machine and iStock all put one hand out of view).
iStock veered closest to national stereotype, with an unconvincing sombrero. Firefly was at the other end of spectrum, with nothing about the subject suggesting a Mexican heritage.
It’s ultimately another win for Freepik, as Ideogram lets itself down with the rendering of the piano keys and some very localised smoke (someone call the fire brigade!)
Winner: Freepik🥇

Conclusions
Midjourney is no longer out in front. Dream Machine, Freepik, Ideogram and Recraft are all producing high quality images, with strong prompt adherence and decent text rendering.
As with text and video, open-source image generators have come on leaps and bounds, with FLUX.1 [dev] (accessible via Freepik) the current poster child.
There’s still a quality gap between models trained on licensed material (iStock & Firefly) and those that haven’t for most output types.
DALL·E 3 (released over a year ago) is now some way off the pace. If you want to generate photorealistic images or images with text in them, you need to stop trying to do it via ChatGPT/Copilot and head to a dedicated AI image generator.
If you’re after a free generator for light use then Freepik is a good option. It’s fast, easy to use with good prompt adherence and a decent range of features.
If you’re willing to pay, then Ideogram or Recraft are both worthy alternatives to Midjourney. If you want to generate images with text in them then go for Ideogram. If you want to create custom styles or SVGs, go for Recraft. If you want to generate consistent characters, go with Midjourney or Freepik.