
What we choose to share with AI
And how more personal and social AI might change the equation

There’s an old adage in media and tech that ‘If you’re not paying for the product, you are the product’.
Originally coined in relation to ad-funded TV in the 1970s, it became even more apposite in relation to social media, which gathers thousands of data points on each of us individually in order to micro-target ads and content to keep us scrolling/swiping.
Early generative AI products weren’t highly personalised and were largely single-player affairs. Individuals input prompts into chatbots and media generators, and selectively (or sometimes not very selectively) shared outputs on existing platforms.
We’ve had to decide what we feel comfortable inputting into AI products and whether to opt-out of our interactions being used for future model training (updated opt-out instructions below), but the AI models themselves weren’t learning about us over time and sharing outputs typically involved pasting/uploading them elsewhere.
As AI products become both more personalised and more social, the equation is getting more complicated.
Personalised
In June 2023 I identified ‘personal’ as one of eight things generative AI would become ‘more’ in the coming months.
In February 2024 (that counts as ‘coming months’, right?), OpenAI announced its first version of ChatGPT memory, which has since evolved and expanded and become table stakes functionality for AI assistants.
The introduction of MCP (Model Context Protocol) in December 2024 made it much easier for AI developers to offer the option for you to connect your existing personal data stores (email, calendar, documents) with AI tools.
A few weeks ago, former members of Google’s NotebookLM team unveiled Huxe - a mobile app which connects with your calendar and email to create a personalised daily audio briefing. As well as providing an audio summary of your inbox and schedule, Huxe uses its inbox access to guess which news topics are likely to be of interest.
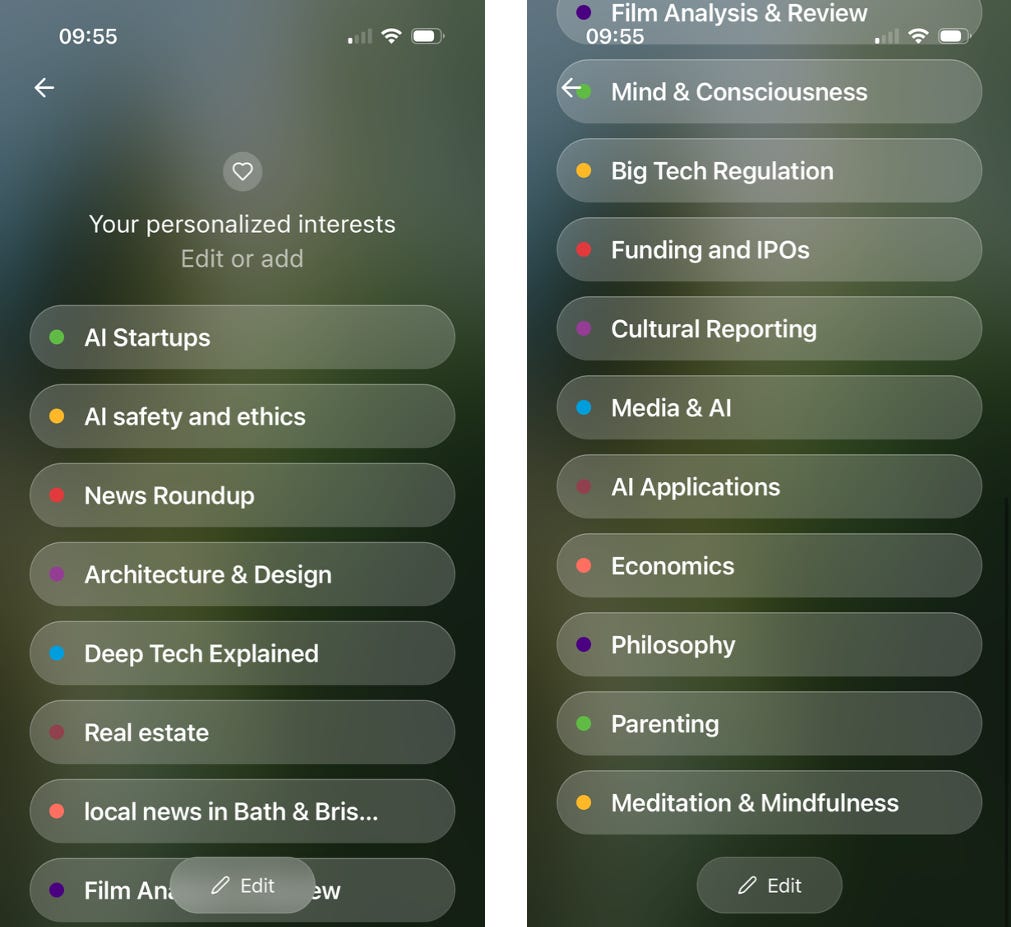
Last month, OpenAI introduced ChatGPT Pulse (to the ChatGPT mobile app for Pro subscribers) - another personalised daily briefing, although delivered as text rather than audio and focused on proactively researching topics it’s inferred (or you’ve told it) are of interest.
Last week, OpenAI launched a Sora mobile app (currently invite-only in the US & Canada), which enables you to create an AI likeness of yourself (video and audio) which can then appear in videos you generate. They’ve dubbed this feature ‘cameos’.
Social
One of my mid-year predictions this year was that ‘AI tools will become more collaborative / multiplayer’.
In just the last fortnight, two of AI’s biggest players, Meta and OpenAI, have released new AI video products (Meta Vibes and the Sora app) with sharing and remixing front and centre.
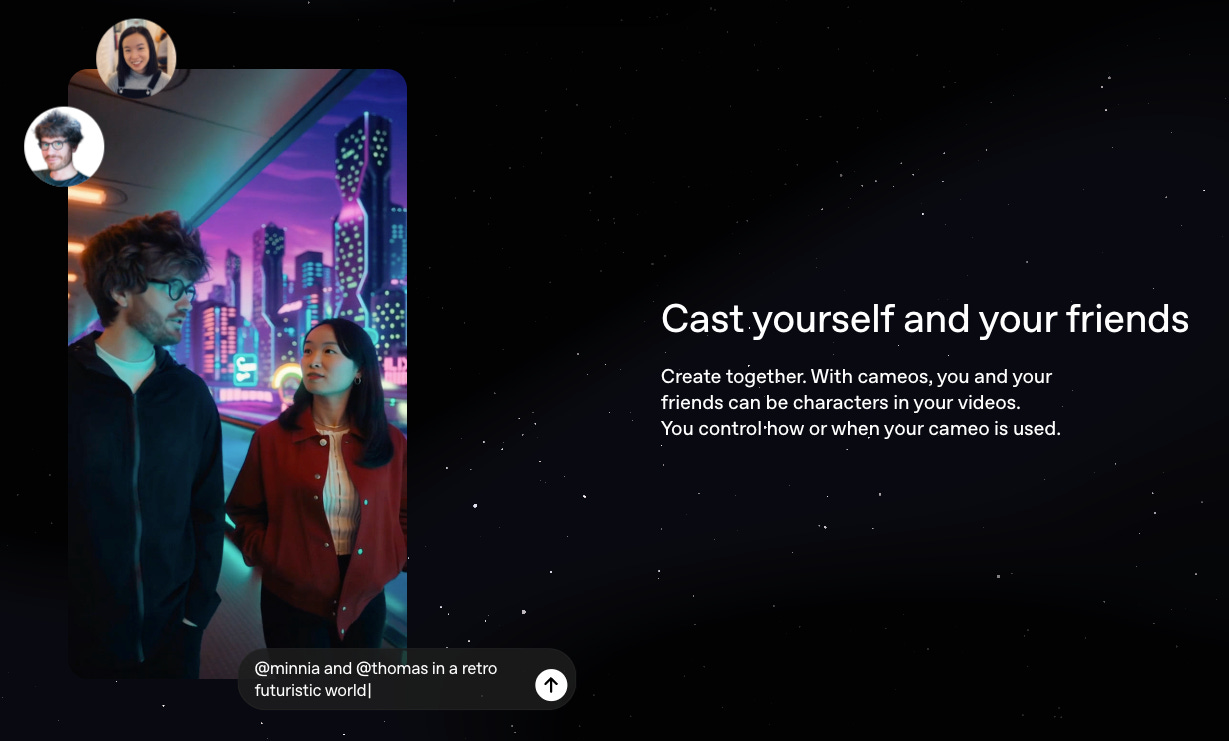
AI products are rapidly becoming more personalised and more social and asking for more of our personal data - including our visual and vocal likeness - to facilitate that. Unfortunately, we don’t have a great track record of carefully weighing up the pros and cons of sharing our data with tech companies.
Privacy vs utility
When thinking about our willingness to trade off privacy for utility, I always think of this 2003 study that found 90% of office workers passing through Waterloo Station were happy to divulge their computer password in exchange for a cheap pen.
Well, I now have an experiment with a larger sample size. A viral app called Neon was, until recently, offering users $30 a day to record their phone calls with the explicit intent to sell the recordings onto AI companies for model training. The app was at no. 2 in Apple’s US App Store social chart before being taken down over a data security issue.

Where are my lines?
I’m often asked how to opt-out of model training (instructions below). I’m sometimes also asked where my own lines are. Here’s where I currently net out:
I have personalisation features enabled on the AI assistants I use regularly.
For me, the utility of AI assistants remembering stuff about me and our past conversations outweighs the risks associated with trusting select AI companies to take good care of my data.
I opt-out of model training for my personal interactions with AI assistants.
Whilst I’m accepting of Anthropic, OpenAI and Google storing my interactions with its AI models to improve my product experience, I don’t want those personal interactions to be used to train public models. However unlikely the scenario (and it is extremely unlikely), I don’t want a future ChatGPT user to ask what school my kids go to and for it to proffer up the correct answer.
I don’t block AI crawlers from accessing my Substack.
Lots of writers are, understandably, angry that their writing has been used to train AI models without consent or remuneration. I don’t feel that way about my own writing. Whilst my intended readership is human, I’m ok with contributing some fresh human-penned writing to the LLM training data pool, although it’s a drop in the ocean - the 100,000+ words I’ve written on this Substack over the last 4 years equate to just 0.0000009% of the total training data a 2025 LLM would likely have been trained on. If OpenAI did want to send me a proportionate cut of their $4.3bn H1 revenues, it would work out at $38.70 (I’ll send you my bank details, Sam).
How to opt-out of model training
I singularly failed to keep my previous ‘how to opt-out of model training’ instructions up-to-date. Here’s an updated guide, correct as of early October 2025. Note that this only applies to the consumer version of these products - if you are using an enterprise version then your interactions are already excluded from model training.
ChatGPT
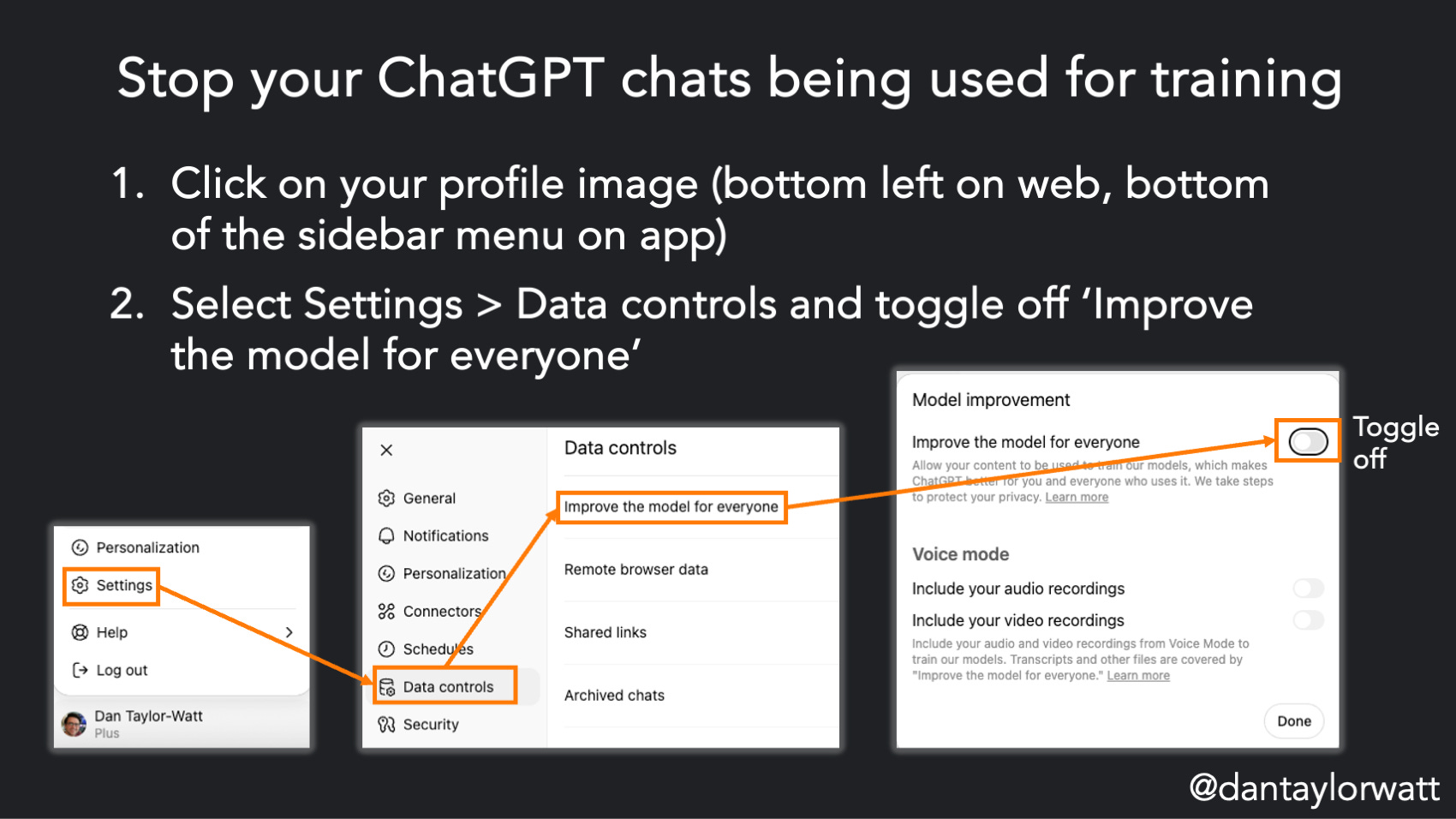
By default, any conversations you have with (or documents you upload to) the free or Plus versions of ChatGPT can be used by OpenAI to train future versions of ChatGPT. Opting out is easy but it’s tucked away under Settings with a slightly cheeky label. To opt out:
Click on your profile image (bottom left on web, bottom of the sidebar menu on app)
Select ‘Settings’ > ‘Data controls’ and toggle off ‘Improve the model for everyone’
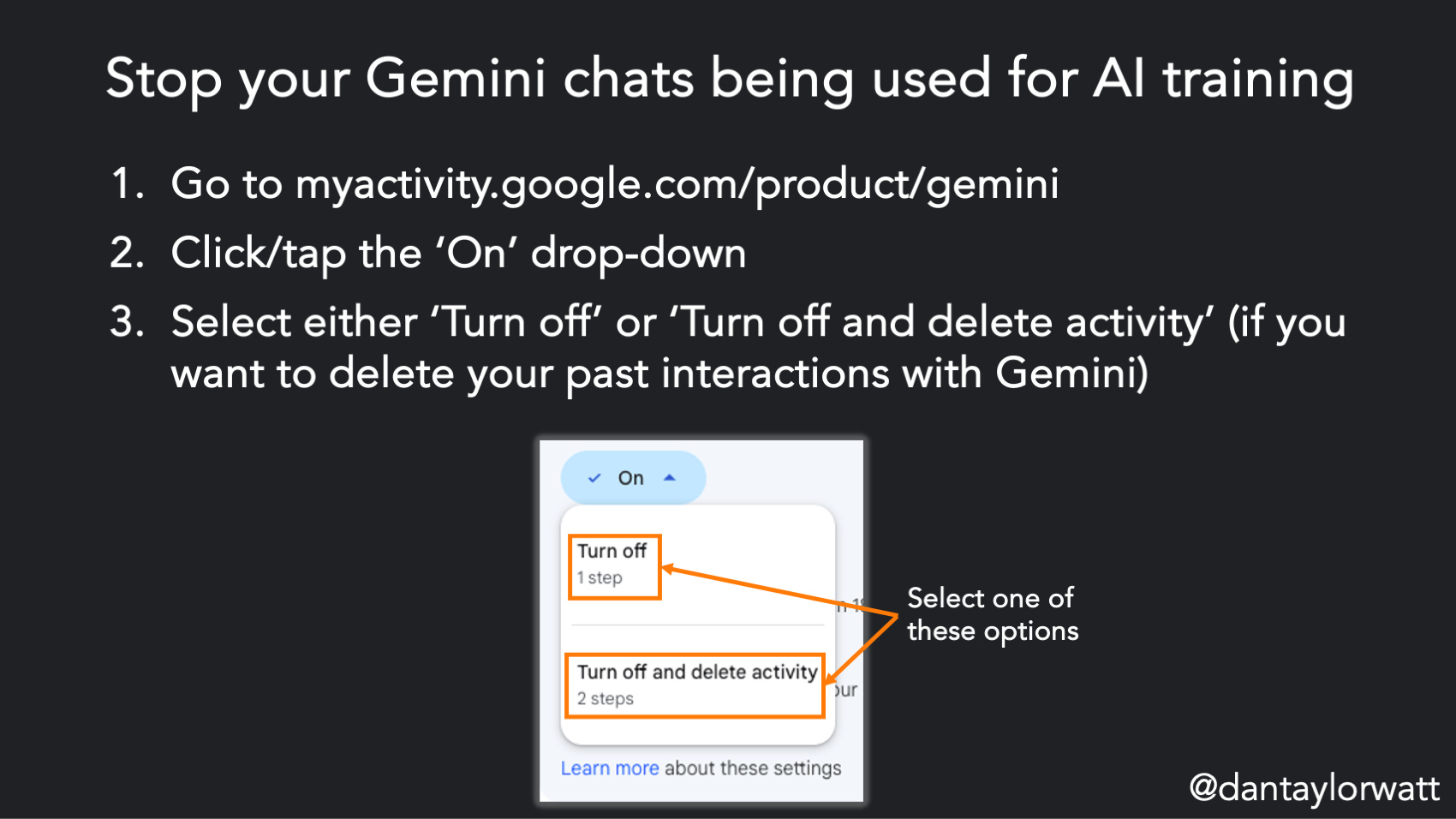
Google Gemini
Frustratingly, there’s currently no way of opting out of AI model training without turning off your Gemini Apps activity. To do so:
Click/tap the ‘On’ drop-down (*terrible interaction design pattern alert*)
Select either ‘Turn off’ or ‘Turn off and delete activity’ (if you want to delete your past interactions with Gemini)
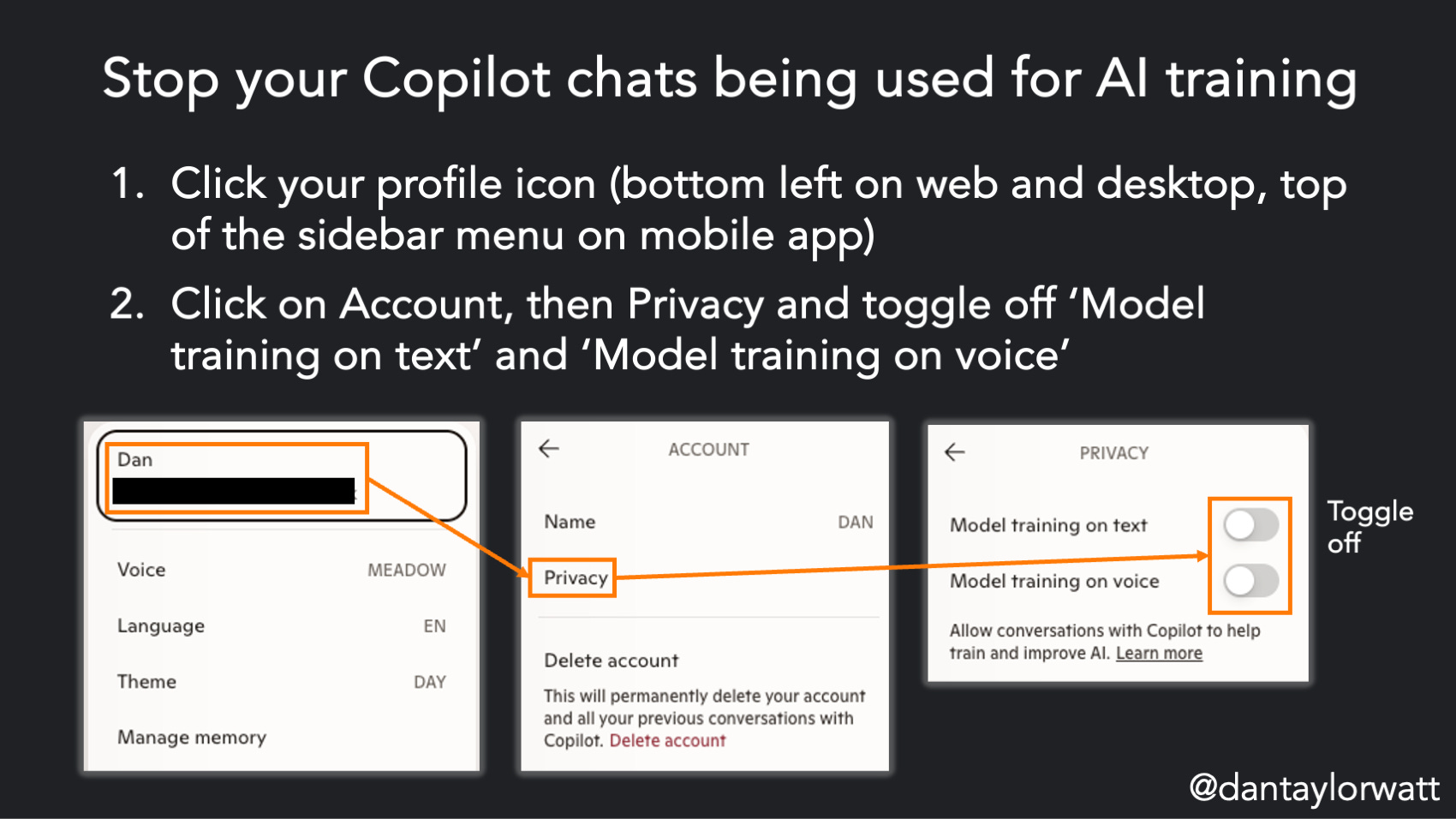
Microsoft Copilot
Click your profile icon (bottom left on web and desktop, top of the sidebar menu on mobile app)
Click on Account, then Privacy and toggle off ‘Model training on text’ and ‘Model training on voice’
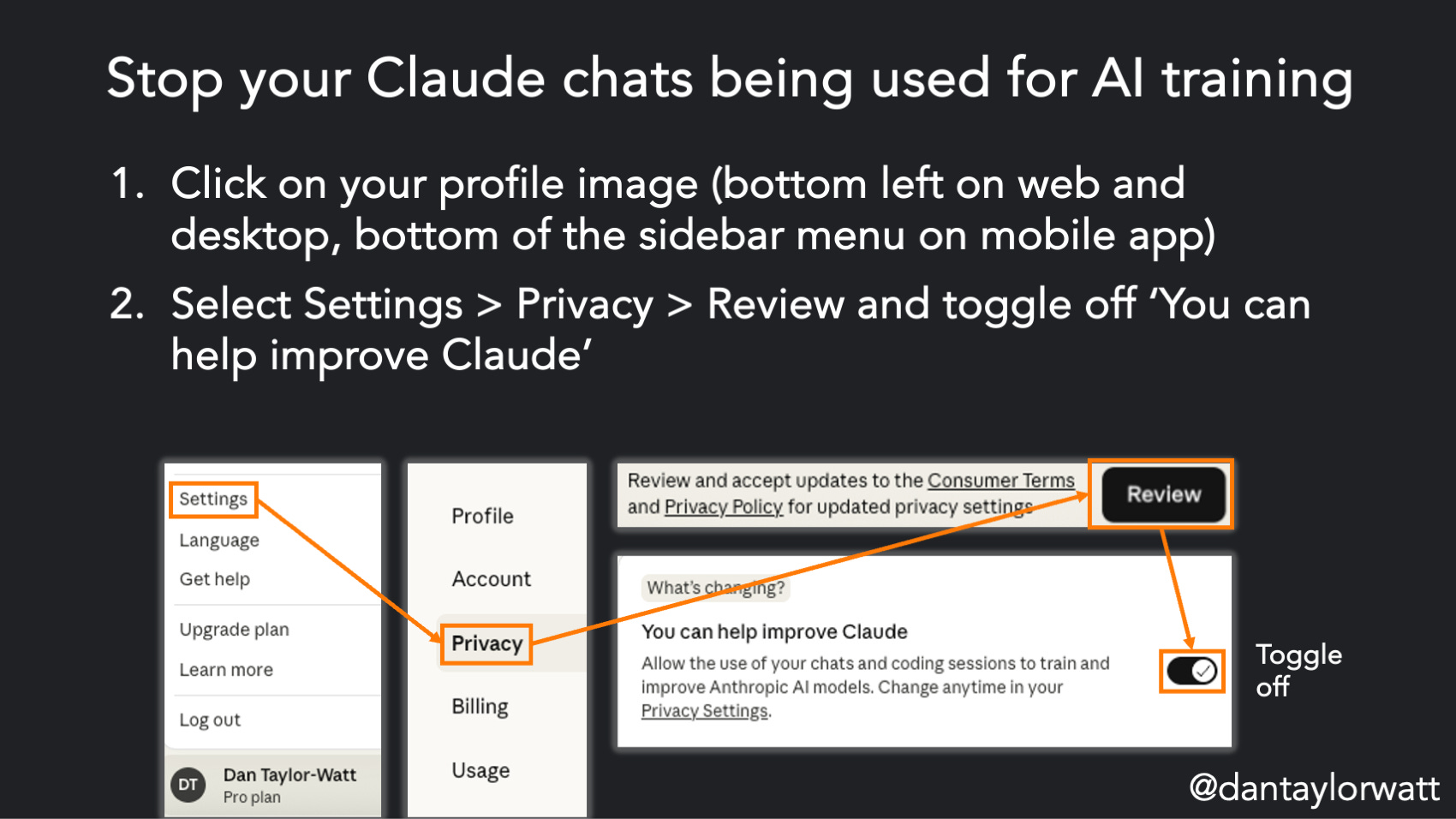
Claude
Anthropic, the company that makes Claude, didn’t used to use any user interactions to train its AI models but it’s updating its Terms and Privacy Policy and you need to opt in or out of model training by 8th October. Here’s how to opt-out:
Click on your profile image (bottom left on web and desktop, bottom of the sidebar menu on mobile app)
Select Settings > Privacy > Review and toggle off ‘You can help improve Claude’
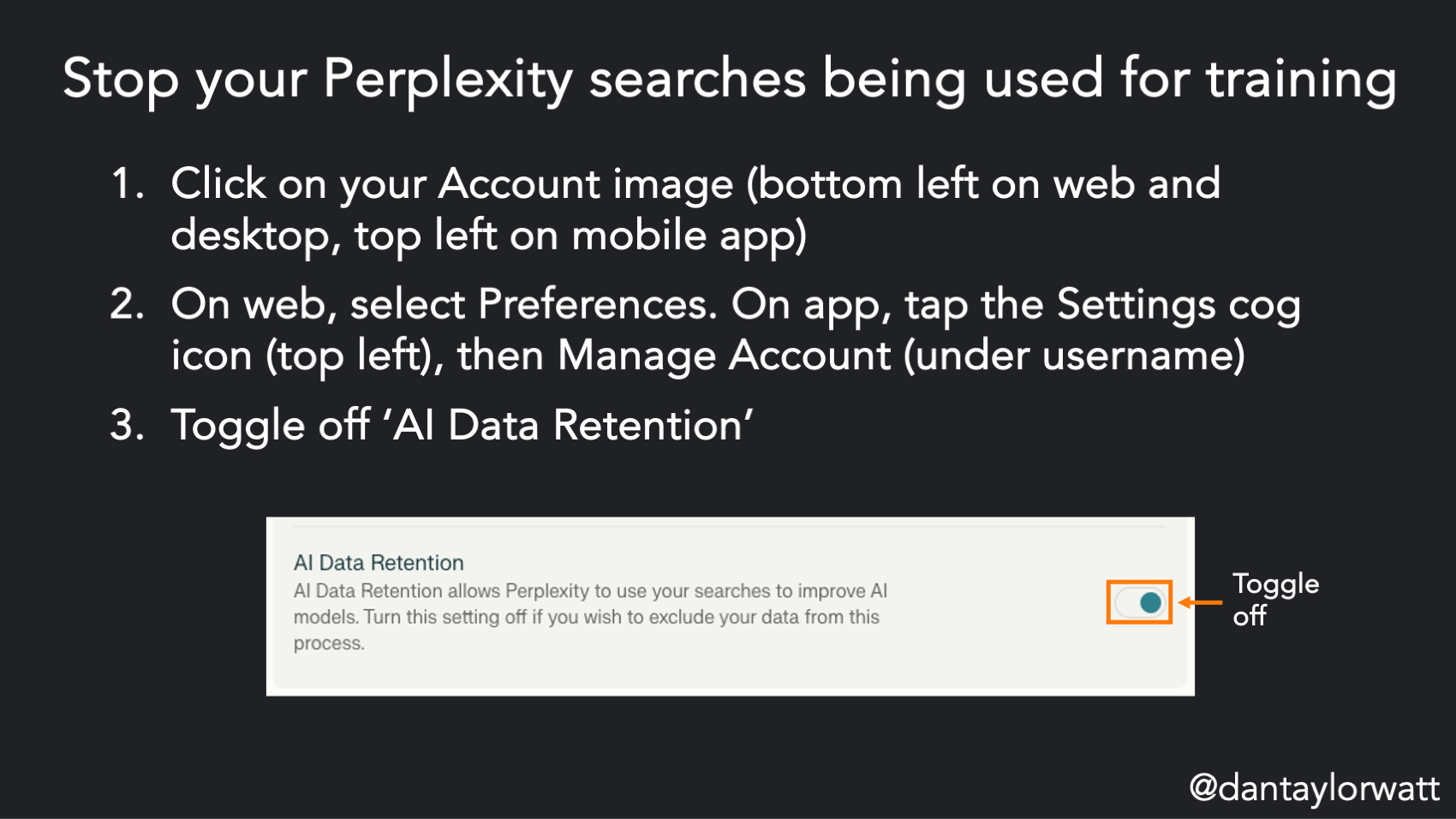
Perplexity
Click on your Account image (bottom left on web and desktop, top left on mobile app)
On web, select Preferences. On app, tap the Settings cog icon (top left), then Manage Account (under username)
Toggle off ‘AI Data Retention’
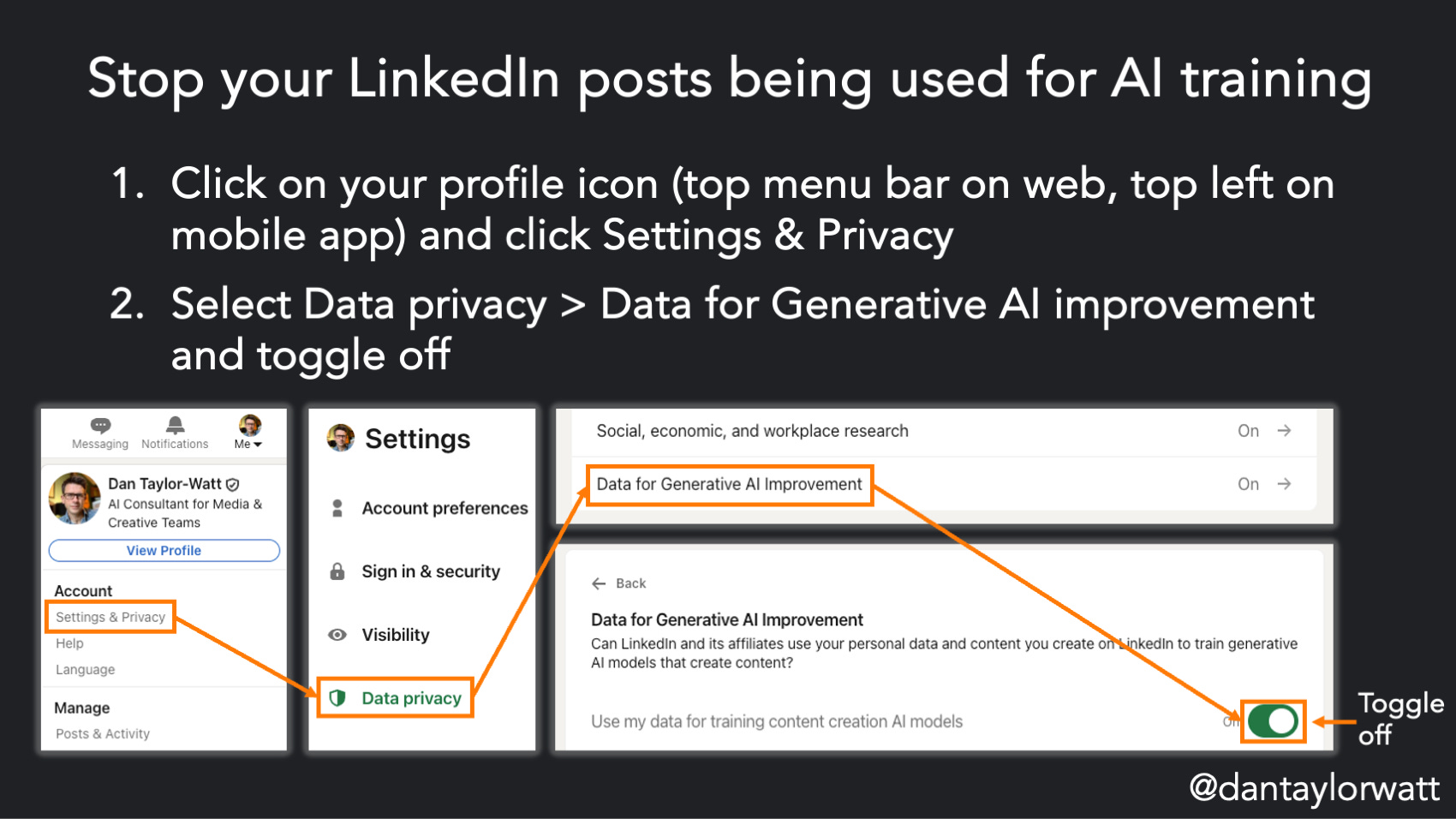
Not an AI product per se, even if its owners would like it to be. However, it has recently updated its UK terms so it will use your LinkedIn data “to improve the content-generating AI that enhances [*cough*] your experience, unless you opt out in your settings” from 3rd November. Here’s how to opt-out:
Click on your profile icon (top menu bar on web, top left on mobile app) and click Settings & Privacy
Select Data privacy > Data for Generative AI improvement and toggle off
Important note: It’s worth being aware that even once you’ve opted out of your content being used for model training, a human reviewer could still see it and/or it could be part of a data breach, so I’d still avoid inputting anything highly sensitive or confidential.