

In the beginning was the (printed) word. Then came photography, recorded audio, video and interactive media.
Each medium had its own tools and workflows. Most companies focused on a single medium. Those that didn’t typically had separate departments specialising in each medium.
The internet, capable of delivering all forms of media, brought some convergence. Big media organisations began talking about ‘multiplatform’ and ‘360 degree’ commissioning and production.
However, outside of the newsroom, most media production teams were still focussed on a single medium. The IP might have been manifest across multiple mediums, but the execution was still divvied up to teams with the requisite medium-specific skills and experience (video, audio, web, app).
More recently, the proliferation of media/social channels and democratisation of ‘good enough’ production tools (smartphone + web tools/apps) has resulted in many more content producers outputting multiple different media formats.
The YouTubeification of podcasting has lured/bounced many audio producers into video production.
Filing a story for BBC News is increasingly unlikely to involve a single medium.
Meanwhile, the rise of the online content creator has spawned a breed for whom producing output in multiple media is the norm.
The evolution of generative AI has followed a similar curve, albeit over a much shorter time period. In early 2023, we had standalone chatbots (ChatGPT), AI image generators (Stable Diffusion, DALL-E), AI video generators (Runway) and AI audio generators (ElevenLabs).
By 2024 we had our first natively multimodal model, Gemini, capable of processing text, images, audio and video.
Fast forward to now and we’re seeing a proliferation of AI tools which are capable of outputting media in multiple different formats from a single set of inputs.
When Google’s NotebookLM (ne. Tailwind) launched in 2023, it was a text-only affair. You uploaded a bunch of documents and then chatted about their contents. In 2024 Google added Audio Overviews, enabling you to generate an AI-hosted podcast based on your notebook with a single click.
The choice of output formats has continued to grow: Mind Maps, narrated slideshows (misleadingly labelled Video Overviews), Briefing Docs, Study Guides and Timelines.
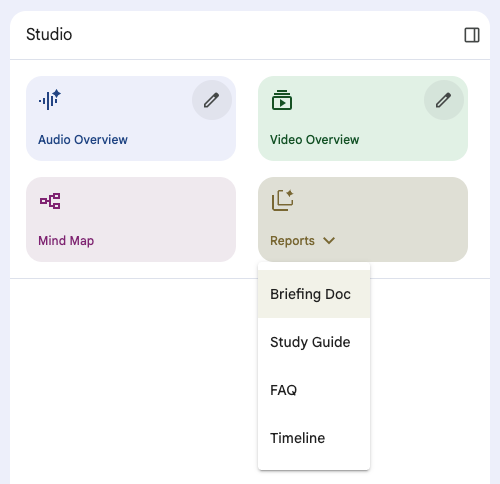
There’s a similar smorgasbord of options offered by newly-launched AI learning platform, Oboe.
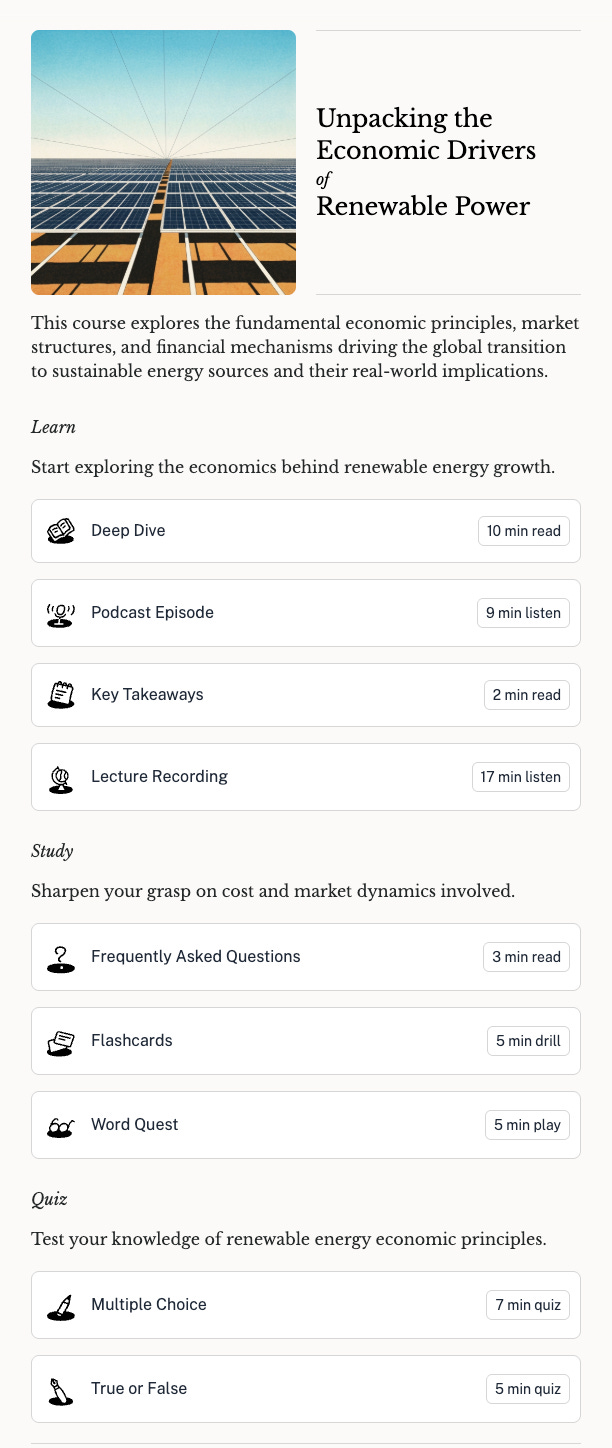
Whilst all of these different formats could be produced using bog-standard Gemini, NotebookLM and Oboe are taking away the prompting overhead and giving you preset buttons to click on. The Oboe interface is particularly slick, with a pinned audio player enabling you to listen to a ‘Podcast Episode’ or ‘Lecture Recording’ (much more evocative descriptors than NotebookLM’s) whilst browsing the other text, visual and interactive formats.
The foregrounding of ‘time to consume’ is also notable - a critical piece of metadata in the attention economy, helping users match media to their available time, and factor time into their can-I-be-bothered calculus (I always appreciate it when platforms/publications foreground this metadata - e.g. Substack, Storythings). Reversioning media for users’ available time was a common area of exploration while I was at the BBC. AI makes duration of media much easier to configure.
Whilst the implications for formal and informal learning are obvious and profound, I believe this one-click dynamic content reversioning is also set to have an impact on media production more generally.
Whilst the quality won’t typically be as good as a hand-crafted piece of media, the ability to take media in one format and use AI to rapidly reversion it into a different format feels like it will increasingly be offered, and accepted by content producers looking to make their content accessible across a vast array of platforms and services.
For writers wanting to create a podcast from their written material, to podcasters wanting to create visuals for YouTube and Spotify without filming, to artists and video producers wanting to make games and animations that reflect their visual style and storytelling (side note: I love this example of AI being used to apply artist Paul Flores’ distinctive art style to an animated world).
Of course this capability will also be used for churning out derivative slop, but I’m more optimistic than most that we, and the algorithms, will get better at sidestepping the slop in favour of more substantive content.
As is so often the way, the question will be to what extent start-ups can scale sticky standalone products on top of these multimodal production capabilities before the AI giants decide it’s worth productising these features within their assistants, which already have scale.
It strikes me that how effectively you can describe new AI capabilities is becoming as important as adding them in the first place. As of last week, Claude can create and edit Excel sheets, Word docs and PowerPoint presentations but is describing this capability (currently only available on the more expensive plans) as ‘Upgraded file creation and analysis’.
AI video startup Higgsfield is currently carrying out something of a masterclass in how to package up AI functionality in an appealing way for audiences (separate post on this to follow).